
Neural networks explained delve into the fascinating world of artificial intelligence. These interconnected systems mimic the human brain, learning from data and performing complex tasks. This guide explores the fundamental concepts, various architectures, and practical applications of neural networks, from their basic structure to advanced techniques. We’ll cover everything from data handling and training to ethical considerations and future trends.
This in-depth exploration will equip you with a solid understanding of neural networks, enabling you to appreciate their versatility and potential.
Introduction to Neural Networks: Neural Networks Explained
Neural networks are a powerful class of machine learning algorithms inspired by the structure and function of the human brain. They consist of interconnected nodes, organized in layers, that process information in a hierarchical manner. This allows them to learn complex patterns and relationships from data, enabling them to make predictions and classifications. The core concept is that these networks adjust their internal connections, learning from examples, to improve their performance.Neural networks, at their core, are computational models designed to mimic the interconnectedness of neurons in the brain.
They consist of interconnected nodes, organized into layers, which process information and learn from data. These nodes are linked by weighted connections that determine the strength of the signal passing between them.
Basic Structure and Components
Neural networks are composed of interconnected nodes, arranged in layers. The input layer receives the initial data, hidden layers perform complex computations, and the output layer produces the final result. Each connection between nodes has an associated weight, representing the strength of the connection. These weights are crucial to the learning process, as they are adjusted during training to optimize the network’s performance.
Interconnected Nodes and Weighted Connections
The interconnected nodes in a neural network are organized in layers. Input data is fed into the input layer, and the information is then passed through intermediate layers (hidden layers) before being processed by the output layer. Connections between these nodes have associated weights, which are crucial to the learning process. These weights determine the influence of one node on another, and they are adjusted during training to minimize errors in predictions.
Learning from Data
Neural networks learn from data by adjusting the weights of connections between nodes. This process, known as training, involves presenting the network with a set of input-output pairs. The network calculates an output for each input, and the difference between the actual output and the desired output is used to update the weights. This iterative process continues until the network achieves a satisfactory level of accuracy.
A common example is training a network to recognize handwritten digits. The network is presented with numerous examples of handwritten digits, and the weights are adjusted until the network can accurately classify new, unseen handwritten digits.
Different Types of Neural Networks
Different architectures cater to various tasks. Each type has unique strengths and weaknesses.
| Type | Structure | Strengths | Weaknesses |
|---|---|---|---|
| Feedforward | Information flows in one direction, from input to output. No cycles. | Simple to implement, computationally efficient. | Cannot handle sequential data or tasks requiring memory. |
| Recurrent | Information can flow in both directions, and has loops. They retain information over time. | Excellent for tasks involving sequences, such as natural language processing, time series prediction, and speech recognition. | Can be computationally more intensive and prone to vanishing gradients. |
| Convolutional | Specialized for processing grid-like data, like images and videos. Uses filters to extract features. | Highly effective for image recognition, object detection, and image classification tasks. | Not as suitable for tasks not involving grid-like data. |
Learning Processes in Neural Networks
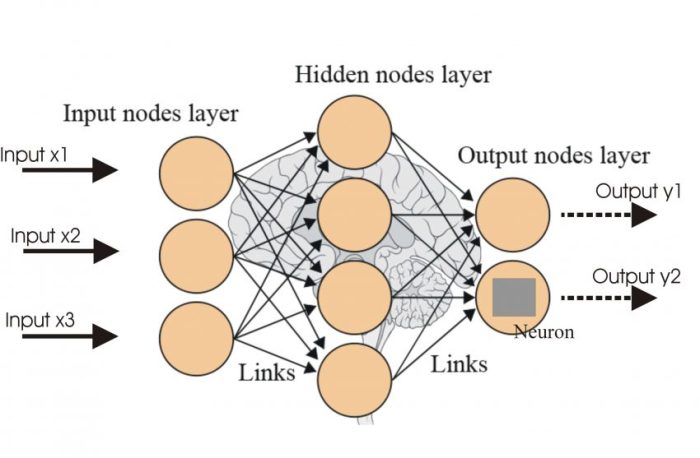
Neural networks learn from data by adjusting the connections (weights) between their neurons. This process, called training, aims to minimize errors in predictions. Different algorithms and optimization techniques are employed to achieve this, each with its own strengths and weaknesses. Understanding these methods is crucial for building effective and accurate neural networks.
Backpropagation Algorithm
Backpropagation is a crucial algorithm for training artificial neural networks. It calculates the gradient of the loss function with respect to the network’s weights. This gradient indicates the direction and magnitude of adjustments needed to reduce the error. The algorithm works by propagating the error backward through the network, layer by layer, allowing for efficient weight updates.
Optimization Methods
Various optimization methods are used to adjust network weights during training. These methods aim to find the optimal set of weights that minimize the error function. Common optimization methods include gradient descent, stochastic gradient descent, and Adam. Each method has its own characteristics, impacting training speed and the final performance of the network.
Gradient Descent
Gradient descent is a fundamental optimization algorithm used to minimize a function by iteratively moving in the direction of the negative gradient. In neural networks, the function to be minimized is the loss function, measuring the difference between the network’s predictions and the actual values. By iteratively adjusting weights in the direction of the negative gradient, the network progressively learns to reduce errors.For example, imagine a simple linear regression problem.
The goal is to find the best-fit line through a dataset of points. Gradient descent helps to determine the slope and y-intercept of the line that minimizes the squared differences between the predicted and actual values of y for each data point. This iterative process continues until the line best represents the data, thus minimizing the error.
Steps in Training a Neural Network
- Data Preparation: This stage involves collecting and preprocessing the dataset. Data is typically split into training, validation, and testing sets to evaluate the model’s performance. Crucially, the data should be normalized or standardized to prevent features with larger values from dominating the learning process.
- Model Initialization: The neural network architecture (number of layers, neurons per layer) is defined, and weights and biases are randomly initialized. The network is ready to receive data for training.
- Forward Propagation: Input data is fed through the network, layer by layer, to produce predictions. This process involves calculating the output of each neuron based on the weighted sum of its inputs and an activation function.
- Loss Calculation: The difference between the predicted output and the actual target output is measured using a loss function (e.g., mean squared error). This loss value represents the error in the network’s prediction.
- Backpropagation: The error is propagated back through the network to calculate the gradient of the loss function with respect to each weight. This gradient provides information about how to adjust the weights to reduce the error.
- Weight Update: The weights are adjusted based on the calculated gradient using an optimization algorithm like gradient descent. This step aims to minimize the loss function and improve the network’s performance.
- Iteration and Evaluation: Steps 4-6 are repeated multiple times (epochs) using the training data. The network’s performance is evaluated on the validation set after each epoch to monitor progress and avoid overfitting. If the validation loss plateaus or increases, the training process might be stopped early to prevent overfitting.
| Step | Description |
|---|---|
| Data Preparation | Collect and preprocess the data. Split into training, validation, and testing sets. |
| Model Initialization | Define the architecture and initialize weights/biases. |
| Forward Propagation | Input data flows through the network to produce predictions. |
| Loss Calculation | Measure the difference between predictions and actual values using a loss function. |
| Backpropagation | Propagate the error backward to calculate gradients. |
| Weight Update | Adjust weights based on the calculated gradients. |
| Iteration and Evaluation | Repeat steps 4-6. Evaluate performance on the validation set. |
Architectures and Variations
Neural networks come in diverse architectures, each tailored for specific tasks. Understanding these architectures is crucial for selecting the right network for a given problem. Different architectures leverage various computational mechanisms to excel in diverse applications, from image recognition to natural language processing. The fundamental components remain similar, but the arrangement and connections between these components determine the network’s capabilities.Different architectures offer varying strengths and weaknesses, and the choice depends heavily on the specific problem being addressed.
Factors such as the nature of the data, the desired outcome, and the computational resources available play a role in selecting the most suitable architecture.
Multilayer Perceptron (MLP)
The Multilayer Perceptron (MLP) is a fundamental feedforward neural network. It consists of interconnected layers of nodes, with each layer’s output feeding into the next. The input layer receives the initial data, the hidden layers process the data, and the output layer produces the final result. MLP architectures are versatile and can be applied to various tasks, including classification and regression.A key characteristic of MLPs is their ability to learn complex relationships within data.
The multiple layers allow for hierarchical representations, enabling the network to capture intricate patterns.
Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs) are specifically designed for processing grid-like data, such as images and videos. Their architecture leverages convolutional layers, which extract features from the input data. These features are then passed through pooling layers, which reduce the dimensionality of the data while retaining essential information. This structure is highly effective for tasks like image classification, object detection, and image segmentation.CNNs excel at identifying spatial relationships within data.
They learn hierarchical representations of features, starting with simple edges and progressing to complex objects. This hierarchical approach allows CNNs to effectively recognize patterns and objects in images and videos. For instance, in medical imaging, CNNs can assist in detecting anomalies or identifying specific tissues with high accuracy.
Recurrent Neural Networks (RNNs)
Recurrent Neural Networks (RNNs) are designed to handle sequential data, such as text, time series, and audio. Unlike feedforward networks, RNNs maintain an internal state that captures information from previous inputs. This internal state allows RNNs to process sequential information effectively. RNNs are well-suited for tasks like natural language processing, machine translation, and speech recognition.The key characteristic of RNNs is their ability to remember past information.
Neural networks are essentially complex systems mimicking the human brain. They’re crucial for processing information and learning patterns, and their applications are expanding rapidly. This intricate process is finding practical applications in Integrated Digital Technologies Glendale CA, a modern overview of which can be found here. Ultimately, understanding neural networks is key to unlocking their potential in various fields.
This internal state allows them to understand context and dependencies in sequential data. For example, in language translation, RNNs can understand the context of a sentence to accurately translate the meaning. A key challenge with traditional RNNs is the vanishing gradient problem.
Activation Functions
Activation functions introduce non-linearity into the network. Without them, the network would essentially be a linear model. These functions introduce complexity and enable the network to learn more complex patterns and relationships in data. The choice of activation function can significantly impact the network’s performance and training time.Common activation functions include ReLU (Rectified Linear Unit), sigmoid, and tanh.
ReLU is a popular choice due to its simplicity and efficiency. Sigmoid and tanh, while commonly used, can suffer from the vanishing gradient problem.ReLU is generally preferred for its speed and efficiency in training. The choice of activation function depends on the specific task and the characteristics of the data.
Applications of Neural Networks

Neural networks, with their ability to learn complex patterns from data, have found widespread application across various fields. Their adaptability and powerful predictive capabilities make them invaluable tools for solving intricate problems in areas like image recognition, natural language processing, speech recognition, and financial modeling. This section delves into specific examples of how neural networks are employed in these domains.
Image Recognition Applications
Neural networks excel at image recognition tasks, enabling computers to “see” and interpret visual information. Convolutional Neural Networks (CNNs) are particularly well-suited for this purpose. Their architecture effectively extracts hierarchical features from images, allowing them to identify objects, faces, and other visual patterns.
- Object Detection: CNNs are crucial in identifying and localizing objects within images. Self-driving cars, for instance, use CNNs to detect pedestrians, traffic signals, and other vehicles, enabling safe navigation. A typical application might involve training a CNN on a large dataset of images labeled with different objects to allow the network to learn the features associated with each object and then apply this knowledge to new, unseen images.
- Facial Recognition: The ability of CNNs to recognize faces is employed in security systems, social media tagging, and access control. These networks can identify individuals based on their unique facial features, learning from a vast collection of facial images. In practice, training data might include images of diverse individuals, ensuring robustness across different lighting conditions and facial expressions.
- Medical Image Analysis: CNNs can assist in analyzing medical images like X-rays, CT scans, and MRIs. By learning to recognize patterns indicative of diseases or anomalies, they can aid in faster and more accurate diagnoses. A crucial example involves training a CNN on a dataset of labeled medical images to distinguish between cancerous and healthy tissue.
Natural Language Processing Tasks
Neural networks have revolutionized natural language processing (NLP), enabling computers to understand, interpret, and generate human language. Recurrent Neural Networks (RNNs) and their variants, like Long Short-Term Memory (LSTM) networks, are particularly effective in handling sequential data like text.
- Machine Translation: Neural machine translation systems, often based on sequence-to-sequence models using RNNs, translate text between languages with remarkable accuracy. These systems learn the intricate relationships between words and phrases in different languages from vast datasets of translated text. For example, a network might be trained on a large corpus of English-French translations.
- Sentiment Analysis: Neural networks can determine the sentiment expressed in text, classifying it as positive, negative, or neutral. This capability is used in customer feedback analysis, social media monitoring, and market research. Examples include analyzing reviews to gauge public opinion about a product or service, or determining the tone of a social media conversation.
- Text Summarization: Neural networks can condense large amounts of text into concise summaries. This application is helpful for news aggregation, information retrieval, and content creation. A system might be trained on a corpus of articles and summaries to learn how to extract key information.
Speech Recognition Applications
Neural networks are fundamental to modern speech recognition systems. Hidden Markov Models (HMMs) and deep neural networks (DNNs) are frequently combined for accurate and robust speech recognition.
- Voice Assistants: Voice assistants like Siri, Alexa, and Google Assistant rely heavily on neural networks to accurately transcribe and understand spoken commands. These systems process audio signals and convert them into text, allowing users to interact with devices through voice commands. This often involves training a model on a vast dataset of audio recordings paired with corresponding transcripts.
- Dictation Software: Neural networks power dictation software, allowing users to dictate text directly into computers. These systems are used in various applications, from note-taking to creating documents. A crucial aspect is the ability of the system to handle different accents and speaking styles.
- Speech-to-Text Systems: These systems convert spoken language into written text, enabling accessibility for individuals with disabilities. Neural networks are key to accurate transcription in various settings, from medical consultations to courtroom proceedings.
Financial Modeling Applications
Neural networks have shown potential in financial modeling, particularly in areas where complex patterns and relationships are difficult to capture using traditional methods.
- Algorithmic Trading: Neural networks can analyze market data to identify patterns and make predictions about future price movements. This information can be used to develop trading strategies that aim to capitalize on these insights. For instance, a model might be trained on historical stock prices and market indicators to predict future price trends.
- Fraud Detection: Neural networks can detect fraudulent transactions by identifying patterns in transaction data that are indicative of fraud. This capability is crucial for protecting financial institutions from losses. A network could be trained on a dataset of legitimate and fraudulent transactions to identify subtle characteristics associated with fraud.
- Credit Risk Assessment: Neural networks can assess credit risk by analyzing various factors about borrowers, such as income, credit history, and debt levels. This helps financial institutions make informed decisions about lending. A model trained on historical data of borrowers and their repayment behavior could assess the risk associated with new loan applications.
Data Handling and Preprocessing
Preparing data for neural network training is a crucial step, often consuming a significant portion of the overall project time. The quality and representativeness of the input data directly impact the model’s performance. Effective preprocessing techniques ensure the data is in a suitable format for the network, enhancing its learning capacity and reducing potential biases.
Data Preparation for Training, Neural networks explained
Neural networks thrive on structured numerical data. Therefore, raw data often needs transformation to be usable. This involves tasks such as converting categorical variables into numerical representations (one-hot encoding), handling missing values, and ensuring data consistency across features. Properly formatted data facilitates efficient learning and prevents the network from misinterpreting the relationships between variables. For example, a dataset describing customer preferences might require encoding categorical variables like “preferred payment method” into numerical representations before feeding it to the network.
Data Normalization and Standardization
Data normalization and standardization are vital for preventing features with larger values from dominating the learning process. Features with larger values can disproportionately influence the network’s weights, potentially leading to inaccurate or biased results. Normalization scales data to a specific range, often between 0 and 1, while standardization centers the data around a mean of 0 and a standard deviation of 1.
These techniques ensure that all features contribute equally to the training process, leading to a more balanced and accurate model. Consider a dataset with features like age (in years) and income (in dollars). Normalization or standardization would prevent the income feature from overshadowing the age feature.
Handling Missing Data
Missing data is a common issue in real-world datasets. Several methods can address this challenge. One approach is to remove rows containing missing values, but this can lead to data loss if the missing data is not randomly distributed. Alternatively, imputation techniques can fill in missing values using various strategies. These strategies include using the mean, median, or mode of the feature for imputation, or more advanced methods like using K-Nearest Neighbors to estimate missing values based on similar data points.
The choice of method depends on the nature of the missing data and the dataset’s characteristics. For instance, if a customer’s age is missing in a survey, imputation using the mean or median age of other respondents could be a suitable strategy.
Data Preprocessing Techniques
- Data Cleaning: This process involves identifying and handling errors, inconsistencies, and outliers in the dataset. This is a crucial step as these issues can negatively impact the performance of the neural network. Examples include fixing typos, handling duplicate entries, and removing or correcting incorrect values.
- Feature Scaling: This involves transforming numerical features to a common scale, often to prevent features with larger values from dominating the learning process. Normalization and standardization are two common methods. Normalization scales data to a specific range (e.g., 0-1), while standardization centers data around a mean of 0 and a standard deviation of 1.
- Feature Engineering: This involves creating new features from existing ones to improve the model’s performance. This might involve creating interaction terms between features, aggregating related features, or applying domain-specific knowledge. For instance, in a dataset of customer purchases, creating a feature representing the total spending in a specific time period could be beneficial.
- Data Transformation: This refers to converting data into a suitable format for the neural network. This includes converting categorical variables into numerical representations (e.g., one-hot encoding) and handling time series data.
Summary Table of Data Preprocessing Techniques
| Technique | Description | Example |
|---|---|---|
| Data Cleaning | Identifying and handling errors, inconsistencies, and outliers | Correcting typos, removing duplicates |
| Feature Scaling | Transforming numerical features to a common scale | Normalization, standardization |
| Feature Engineering | Creating new features from existing ones | Creating interaction terms, aggregating features |
| Data Transformation | Converting data to a suitable format | One-hot encoding, handling time series |
Evaluation Metrics and Performance
Assessing the effectiveness of a neural network hinges on evaluating its performance. Choosing appropriate metrics and understanding their interpretations is crucial for identifying strengths and weaknesses, enabling informed adjustments to the model’s architecture and training process. This section delves into common evaluation metrics, the nuances of overfitting and underfitting, and strategies for mitigating these issues.
Common Evaluation Metrics
Evaluating neural network performance relies on quantifiable metrics. These metrics provide a numerical representation of the model’s ability to accurately predict outcomes based on input data. Key metrics include accuracy, precision, recall, and F1-score.
- Accuracy measures the overall correctness of predictions. It’s calculated as the ratio of correctly classified instances to the total number of instances. A high accuracy score suggests a well-performing model that correctly classifies most instances. For example, an accuracy of 95% indicates that the model correctly classified 95 out of every 100 instances. However, accuracy alone might not capture the nuances of the model’s performance, especially in imbalanced datasets.
- Precision quantifies the accuracy of positive predictions. It’s calculated as the ratio of correctly predicted positive instances to the total number of instances predicted as positive. A high precision score indicates that the model is reliable in identifying positive instances. For example, a precision of 80% for spam detection means that 80% of the emails flagged as spam were actually spam.
- Recall measures the model’s ability to identify all relevant instances. It’s calculated as the ratio of correctly predicted positive instances to the total number of actual positive instances. A high recall score suggests that the model captures a large proportion of the actual positive instances. For example, a recall of 90% for a medical diagnosis model means that 90% of the actual patients with the condition were correctly identified.
- F1-score provides a balanced measure of precision and recall. It’s the harmonic mean of precision and recall. A high F1-score suggests a good balance between correctly identifying positive instances and minimizing false positives.
Interpreting Evaluation Metrics
Understanding the context and nuances of each metric is critical. A high accuracy score might be misleading if it’s achieved by correctly classifying a majority class while failing to identify a minority class. A good evaluation involves considering multiple metrics and understanding their interplay.
Overfitting and Underfitting
Neural networks can exhibit either overfitting or underfitting. Overfitting occurs when a model learns the training data too well, including noise and irrelevant details, leading to poor generalization on unseen data. Underfitting occurs when the model is too simple to capture the underlying patterns in the data.
Handling Overfitting
Overfitting can be mitigated by several strategies.
- Data Augmentation: Creating synthetic data points to expand the training dataset can help the model generalize better. Adding variations to existing images, for example, can be used for image classification.
- Regularization: Techniques like L1 and L2 regularization penalize large weights, discouraging the model from overly fitting to the training data. This prevents the model from relying heavily on specific features.
- Dropout: A regularization technique where neurons are randomly deactivated during training, forcing the model to learn more robust features.
- Early Stopping: Monitoring the model’s performance on a validation set and stopping the training process when the validation error begins to increase. This prevents the model from overfitting the training data.
Practical Considerations
Putting neural networks into practice requires careful consideration of various factors beyond the theoretical foundations. These practical considerations ensure efficient and effective deployment of these powerful models. Understanding resource requirements, leveraging hardware acceleration, and choosing appropriate programming frameworks are crucial steps in building and utilizing neural networks.
Computational Resources
Training large neural networks often demands significant computational resources. The complexity of the network architecture, the size of the training dataset, and the desired accuracy all contribute to the computational demands. Processing power and memory capacity are key factors. For instance, a network with millions of parameters and a dataset containing millions of samples will necessitate substantial processing power to perform the necessary calculations and store intermediate results.
Specialized hardware, like GPUs, is often employed to expedite this process.
Hardware Acceleration
Hardware acceleration significantly improves training speed. Graphics Processing Units (GPUs) are particularly well-suited for the parallel computations inherent in neural network training. They excel at handling matrix operations, which are fundamental to neural network computations. Utilizing GPUs can dramatically reduce training time, allowing for more complex models and larger datasets to be handled effectively. The parallel processing capabilities of GPUs enable simultaneous computations on different parts of the data, leading to a substantial increase in training speed.
Programming Frameworks
Numerous programming frameworks simplify the development and deployment of neural networks. TensorFlow and PyTorch are two popular choices. TensorFlow, known for its strong ecosystem and extensive community support, offers a flexible and scalable platform. PyTorch, with its dynamic computation graph, provides a more interactive and developer-friendly environment. The choice of framework often depends on the specific project requirements and the developer’s familiarity with each platform.
Python Example (TensorFlow)
This example demonstrates a basic neural network implementation using TensorFlow. It constructs a simple feedforward neural network with one hidden layer.“`pythonimport tensorflow as tf# Define the modelmodel = tf.keras.Sequential([ tf.keras.layers.Dense(128, activation=’relu’, input_shape=(784,)), # Input layer with 784 features tf.keras.layers.Dense(10, activation=’softmax’) # Output layer with 10 classes])# Compile the modelmodel.compile(optimizer=’adam’, loss=’sparse_categorical_crossentropy’, metrics=[‘accuracy’])# Load and preprocess the dataset (e.g., MNIST)(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()x_train = x_train.reshape(60000, 784).astype(‘float32’) / 255x_test = x_test.reshape(10000, 784).astype(‘float32’) / 255# Train the modelmodel.fit(x_train, y_train, epochs=2)# Evaluate the modelloss, accuracy = model.evaluate(x_test, y_test)print(‘Test accuracy:’, accuracy)“`This example demonstrates a fundamental structure.
Real-world applications often involve more complex architectures and data preprocessing steps. The example uses the MNIST dataset, a classic dataset for image recognition tasks. The use of `tf.keras.Sequential` creates a linear stack of layers. The `Dense` layers define fully connected neural network layers. The `input_shape` specifies the input dimension, crucial for correct model definition.
The example trains the model on the training data and then evaluates its performance on the test data.
Neural networks are basically complex systems mimicking the human brain. They’re used for various tasks, and a company like Hikvision Digital Technology Co A Comprehensive Overview Hikvision Digital Technology Co A Comprehensive Overview leverages these networks in their surveillance and security systems. Ultimately, neural networks are powerful tools for pattern recognition and decision-making in many fields.
Ethical Considerations
Neural networks, while powerful tools, raise important ethical concerns. Understanding and addressing these issues is crucial for responsible development and deployment of AI. Bias in training data, potential for unfair outcomes, and societal impacts are significant factors that need careful consideration.
Potential Biases in Neural Network Models
Neural networks learn from data, and if that data reflects existing societal biases, the model will likely perpetuate and even amplify them. For example, if a facial recognition system is trained primarily on images of one demographic, it may perform poorly or inaccurately identify individuals from other groups. This can lead to discriminatory outcomes in areas like law enforcement or security.
Importance of Fairness and Accountability in AI
Fairness and accountability are essential in AI systems. This means that AI systems should not discriminate against any group of people based on protected characteristics. Furthermore, there needs to be a clear understanding of who is responsible for the actions of an AI system, and how to address any negative consequences. This requires transparency in the model’s design and decision-making processes.
Social Implications of Neural Network Applications
Neural network applications have broad social implications, influencing various aspects of our lives. For example, predictive policing algorithms can have a disproportionate impact on certain communities, while automated hiring tools may unintentionally discriminate against particular groups. Careful consideration of these implications is crucial for ensuring equitable and beneficial outcomes.
Examples of Ethical Issues Surrounding Neural Network Use
Several real-world examples highlight ethical concerns related to neural network applications. One example involves loan applications where AI systems might deny loans to applicants from specific demographics, even if their financial profiles are comparable to those of other applicants. Another concern is the use of facial recognition technology in surveillance systems, potentially leading to violations of privacy and civil liberties.
- Bias in Loan Applications: AI-driven loan applications may perpetuate existing biases in lending practices. If the training data predominantly reflects loan approvals for one demographic group, the AI model may unfairly deny loans to others, potentially widening existing economic disparities.
- Predictive Policing: Predictive policing algorithms, designed to identify high-crime areas, can be susceptible to bias if trained on data reflecting existing racial or socioeconomic disparities. This can lead to disproportionate targeting of specific communities, negatively impacting public trust and potentially escalating tensions.
- Facial Recognition in Surveillance: The use of facial recognition in surveillance systems raises concerns about privacy violations. If the data used to train the model is not representative of the population, the system may exhibit bias in identifying individuals, potentially leading to inaccurate or discriminatory outcomes. Additionally, the potential for misuse of this technology, including its application in areas where privacy is a paramount concern, requires careful consideration.
Future Trends in Neural Networks
Neural networks are rapidly evolving, driven by advancements in computing power, data availability, and algorithmic innovation. The future promises exciting developments in neural network architectures, leading to more efficient, powerful, and versatile models. This exploration delves into emerging research areas, highlighting new architectures and techniques, and examining potential future applications.Emerging research focuses on pushing the boundaries of neural network capabilities, addressing challenges in interpretability, and exploring novel applications.
These advancements in specialized hardware are crucial for handling the increasing computational demands of complex neural networks.
Emerging Research Areas
Neural networks are continually evolving, with researchers exploring novel architectures and training techniques. This involves addressing challenges in training efficiency, generalizability, and robustness. Critical areas of research include developing more efficient training algorithms, methods to improve generalization across different datasets and problem types, and building more robust networks that can handle noisy or incomplete data.
New Architectures and Techniques
Several innovative architectures and techniques are emerging. One promising area is the development of graph neural networks (GNNs), which excel at handling complex relational data represented as graphs. These models are well-suited for tasks involving interactions between entities, like social networks analysis and drug discovery. Another significant area of focus is transformer-based models, which have demonstrated remarkable performance in natural language processing tasks.
These models can be adapted and extended to address other domains.
Specialized Hardware Advancements
The escalating computational needs of neural networks necessitate specialized hardware. This includes advancements in hardware like GPUs, TPUs, and specialized ASICs. For example, Tensor Processing Units (TPUs) are designed to accelerate the tensor operations crucial in deep learning. These hardware advancements directly impact training time and model efficiency, paving the way for larger and more complex models to be deployed.
This is crucial for tasks demanding extensive computations, like real-time image processing and large-scale simulations.
Potential Future Applications
Neural networks have already demonstrated impressive performance in various fields. Future applications are poised to expand significantly, spanning various domains. One promising area is personalized medicine, where neural networks can analyze patient data to predict disease risk and tailor treatment plans. Another example is the development of autonomous vehicles, where advanced neural networks will enable self-driving cars to perceive and react to their environment.
Examples of Specific Applications
Neural networks are being increasingly used in tasks requiring pattern recognition and prediction. Examples include:
- Medical Diagnosis: Neural networks can analyze medical images (X-rays, MRIs) to detect anomalies and assist in diagnosing diseases like cancer, aiding in early detection and personalized treatment.
- Financial Modeling: Neural networks can analyze market data and predict future trends, aiding in algorithmic trading and risk assessment.
- Environmental Monitoring: Neural networks can analyze data from sensors to predict weather patterns, monitor pollution levels, and aid in disaster response.
These applications illustrate the broad spectrum of possible future implementations, highlighting the potential of neural networks to revolutionize numerous industries.
Visualization of Neural Networks
Visualizing neural networks is crucial for understanding their internal workings and performance. A well-designed visualization can reveal patterns in data processing, highlight potential issues, and facilitate communication about the network’s behavior. This section delves into various techniques for representing neural networks visually, focusing on their utility for gaining insights into model behavior.
Weight Matrices
Understanding how a neural network processes information often hinges on the weights connecting nodes. Weight matrices, representing these connections, provide a tangible representation of the network’s learned parameters. A visualization of these matrices can reveal patterns in weight distribution, allowing for the identification of important connections and potentially highlighting areas of overfitting or underfitting.
- A weight matrix is a two-dimensional array where each element represents the strength of the connection between two nodes. A high value indicates a strong connection, while a low value signifies a weak connection. Analyzing the distribution of these values can provide insights into the network’s learned features.
- Visualizing weight matrices often involves color-coding, where darker shades represent higher weights and lighter shades represent lower weights. This visual representation makes it easier to spot patterns and clusters of high and low weights.
- By plotting the weight matrix as a heatmap, one can quickly grasp the overall strength of connections within the network, helping to identify crucial connections that significantly influence the network’s outputs.
Activation Maps
Activation maps illustrate the activity of different neurons within the network as it processes input data. These maps visualize the activations of neurons in response to various inputs. They can help to understand which parts of the input are emphasized by the network and where the network focuses its attention.
- Activation maps are often visualized as heatmaps, with higher activation values represented by darker colors. Analyzing these maps across different inputs can reveal how the network responds to variations in input data.
- A useful technique is to generate activation maps for different layers of the network. Comparing activation maps across layers can highlight how features are extracted and transformed as the information flows through the network.
- Visualizing activation maps for different classes in a classification task can help understand how the network distinguishes between them. For example, in image recognition, one might see which parts of an image are activated when classifying an image as a “cat” versus a “dog.”
Graphical Representation of Neural Networks
A graph representation visually displays the structure of a neural network. This visual representation clearly illustrates the connections between nodes and the flow of information within the network.
An example of a neural network visualized using a graph: A perceptron network with three input nodes, two hidden nodes, and one output node. The graph would depict these nodes as circles and the connections between them as lines. Each line would be labeled with the corresponding weight.
Decision Boundaries
Visualizing decision boundaries provides a graphical interpretation of how a neural network classifies different data points. The decision boundary separates the input space into regions where different classes are predicted.
- Decision boundaries can be visualized as contour plots, where the contours represent the decision boundaries. The color or shading of the contours indicates the predicted class.
- In a binary classification problem, the decision boundary might be a line or a curve. In higher-dimensional spaces, the decision boundary could be a hyperplane or more complex shapes.
- Consider a neural network trained to classify images as either “cat” or “dog”. A visualization of the decision boundary in the image feature space could reveal how the network distinguishes between the two classes. Points on one side of the boundary would be classified as “cat,” while points on the other side would be classified as “dog.”
Significance of Visualization
Visualizing neural networks is crucial for understanding and interpreting their behavior. It allows researchers to gain insights into how the network processes information, identifies critical connections, and helps in debugging and optimizing the model.
- Visualization tools enable a better understanding of the network’s internal workings and help in identifying potential issues such as overfitting or underfitting.
- Visualizations can aid in explaining the model’s decisions to stakeholders, enhancing transparency and trust in the model’s output.
- By providing a visual representation of the network’s decision-making process, visualization tools enable researchers to understand the model’s behavior better, which is essential for developing more reliable and robust models.
Ultimate Conclusion
In conclusion, neural networks are powerful tools with a wide range of applications. Understanding their architecture, learning processes, and practical considerations is crucial for harnessing their potential. This guide has provided a comprehensive overview, from basic concepts to cutting-edge research. We hope you’ve found this discussion insightful and inspiring.
Question & Answer Hub
What are the different types of neural networks?
Different neural network types include feedforward, recurrent, and convolutional networks, each suited for various tasks. Feedforward networks process data in one direction, recurrent networks process sequential data, and convolutional networks excel at image and video analysis.
How do neural networks learn?
Neural networks learn through a process called training. They are presented with data, and through algorithms like backpropagation, they adjust their internal connections (weights) to minimize errors in their predictions. This iterative process refines their ability to perform the desired task.
What are some ethical concerns related to neural networks?
Potential biases in the training data can lead to unfair or discriminatory outcomes. Ensuring fairness, accountability, and transparency in neural network applications is crucial to mitigate these risks.
What are the common evaluation metrics for neural networks?
Accuracy, precision, recall, and F1-score are common metrics. They measure the model’s performance in different aspects of prediction accuracy.





